



I. HTTP/2 – introduction▲
Aujourd'hui encore, la majorité du trafic web mondial utilise le protocole HTTP 1.1. Seulement la spécification HTTP 1.1 date déjà de 1997 et a été conçue pour un web d'un autre temps. Voilà à quoi ressemblaient les sites de Google et Apple à ce moment-là :
Des pages simples, peu d'images, un style disons… «vieillot». Les sites ne proposaient que très peu d'interactivité avec l'utilisateur et tout ça se faisait au son de la douce musique d'un modem 56k.
Aujourd'hui le web a considérablement évolué, les pages sont beaucoup plus riches (et donc plus lourdes), plus dynamiques, plus complexes, adaptatives… Le débit des connexions a également énormément augmenté.
Un certain nombre de pratiques voire même du piratage sont donc apparus pour contourner les limitations imposées par HTTP 1.1 afin d'offrir la meilleure qualité de service possible.
En 2009, Google développe un protocole expérimental baptisé SPDY et l'IETFInternet Engineering Task Force va complètement s'appuyer sur ce travail pour proposer HTTP/2 dont la spécification parait en 2015.
Aujourd'hui HTTP/2 est supporté par les principaux navigateurs :

Il en va de même pour la plupart des serveurs HTTP et des CDNContent Delivery Network ce qui permet de favoriser l’adoption de HTTP/2. Adoption déjà réalisée par exemple pour des sites comme Google, Twitter, Wikipedia, Facebook, etc.
Intéressé(e) ? Alors embarquez avec nous et plongez dans les méandres de HTTP/2.
II. HTTP/2 en détail▲
Dans ce premier article de la série, je vous propose de partir à la découverte des évolutions apportées par HTTP/2.
II-A. Tout d'abord, pour nous, développeurs, qu'est-ce que ça change ?▲
De ce côté-là, pas d'inquiétude, HTTP/2 conserve une rétrocompatibilité complète avec HTTP 1.1. Si HTTP/2 n'est pas disponible dans le navigateur du client, le serveur effectuera automatiquement un repli sur HTTP 1.1. Aucun risque donc de rendre votre site inaccessible pour vos utilisateurs si vous décidez de migrer sur HTTP/2.
De plus HTTP/2 conserve l'intégralité de la syntaxe HTTP 1.1 que ce soit les headers, les URI, les méthodes ou encore les codes. La seule chose qui change finalement c'est la manière dont la donnée est segmentée et transportée entre le client et le serveur.
II-B. Voyons ça plus en détail :▲
HTTP 1.1 est un protocole au format texte. En analysant le trafic réseau avec un outil comme WireShark, on peut voir que les données transmises sont parfaitement lisibles :
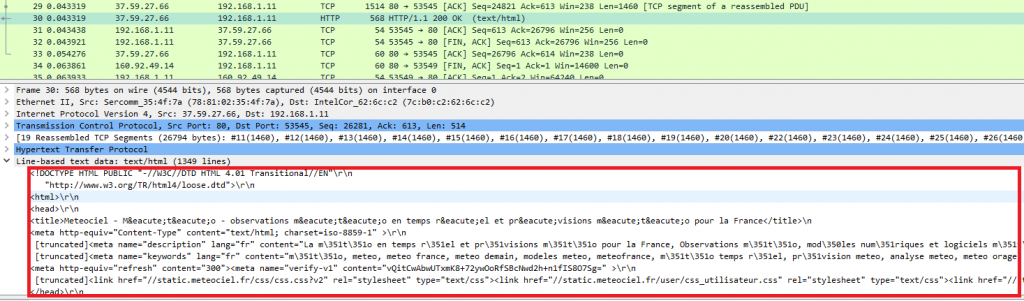
De son côté HTTP/2 est un protocole binaire et la conséquence est que cette fois les données sont illisibles :
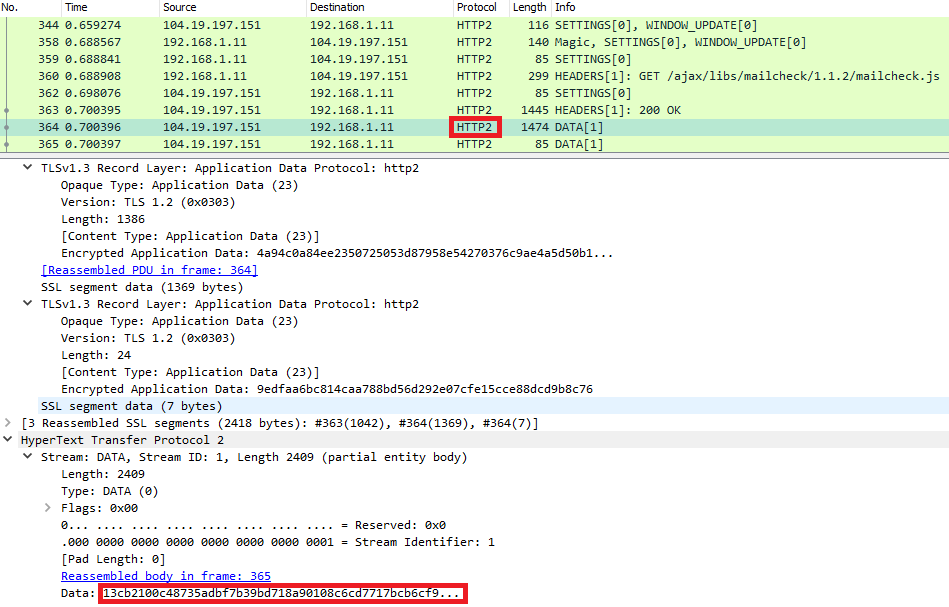
Ce changement de format ne s'est pas fait sans raison et vous comprendrez par la suite pourquoi cela a de l'importance.
II-C. Le multiplexage de flux▲
C'est certainement l'évolution la plus importante de HTTP/2.
=> En HTTP 1.1 on charge les ressources de manière séquentielle, les unes après les autres. Chaque requête ouvre une connexion TCP pour récupérer une ressource. La requête suivante, elle, doit attendre que la connexion soit fermée pour en ouvrir une nouvelle. C'est ce qu'on appelle le « Head-of-line blocking » (en réalité, les connexions ne sont pas fermées après chaque ressource transférée, elles sont par défaut en mode « keep-alive », c'est-à-dire réutilisées pour les prochaines requêtes. En revanche, elles ne peuvent bien transférer qu'une seule ressource à la fois) Exemple ci-dessous avec le chargement d'une image divisée en 190 fragments et dont le chargement final prend 4,27s en HTTP 1.1 :
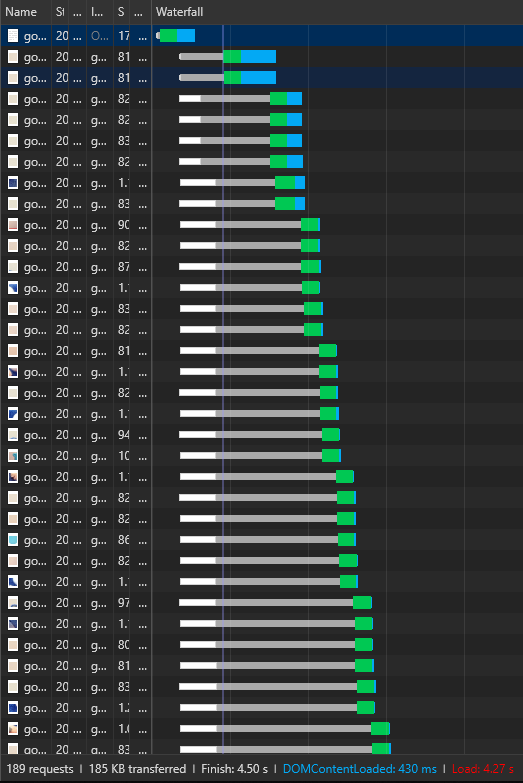
Les navigateurs ouvrent en général plusieurs connexions TCP avec un même serveur pour charger des ressources en parallèle mais le nombre de connexions concurrentes vers un même domaine est limité à 6. De plus, ouvrir une connexion TCP n'est pas gratuit et prend entre 50 et 120 ms.
=> En HTTP /2 on ouvre une seule connexion TCP pour charger toutes les ressources venant de ce domaine, c'est le principe du multiplexage. Cette fois-ci la même image prend 1.24 s pour être complètement chargée :

II-D. Comment ça marche ?▲
Chaque message HTTP est segmenté en frame (rien à voir avec les frames du layer Datalink du modèle OSIOpen Systems Interconnection, ici on reste bien au niveau applicatif à l'intérieur du protocole HTTP). L'un des intérêts de l'utilisation d'un protocole binaire comme décrit plus haut est justement de faciliter cette opération de « framing ».
Chaque frame possède un certain nombre de caractéristiques comme la longueur ou encore le type.
Il y a différents types de frames définis dans la spécification HTTP/2 mais les deux principaux sont DATA et HEADERS (si vous avez déjà utilisé le protocole HTTP vous ne devriez pas être dépaysé).

Mais comment, si toutes mes frames passent par mon unique connexion TCP, puis-je faire le tri à l'arrivée pour reconstituer mon message ?
Chaque frame possède en fait un attribut supplémentaire : le stream ID.
Un stream peut être défini comme une séquence indépendante et bidirectionnelle de frames échangée entre un client et un serveur au sein d'une connexion HTTP/2. On peut grosso modo assimiler un stream à un flux requête + réponse classique en HTTP 1.1.
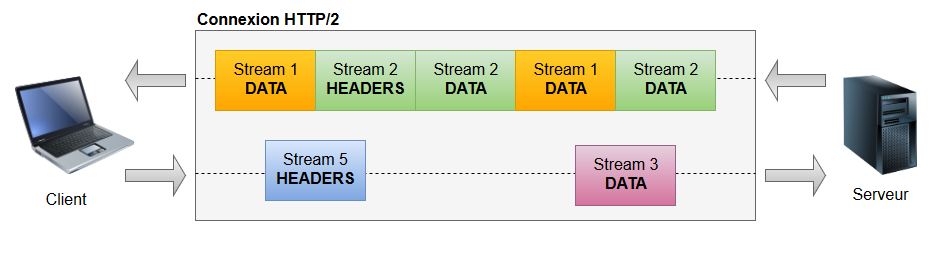
Et là où HTTP/2 innove, c'est qu'une seule connexion TCP peut contenir plusieurs streams ouverts en concurrence. Chaque frame sera raccordée à l'un de ces streams et l'ouverture d'un stream peut se faire aussi bien à l'initiative du client que du serveur.
II-E. Qu'est-ce que cela change ?▲
Cela réduit tout simplement le temps de chargement d'une page en économisant le nombre de connexions TCP ouvertes et en chargeant les ressources en parallèle.
On élimine donc le phénomène de « Head-of-line blocking » (en réalité il est répercuté vers la couche TCP mais cela est hors de la portée de cet article).
De plus, d'une manière plus générale, TCP est optimisé pour des connexions longue durée alors que la plupart des requêtes HTTP sont rapides et éphémères. HTTP/2 permet donc un meilleur usage des connexions TCP, réduisant ainsi la charge réseau globale.
II-F. Pour aller plus loin : la priorisation de stream▲
Vous avez décidé de sauter le pas et de migrer tous vos serveurs HTTP vers HTTP/2. Tout se déroule pour le mieux, vous avez vos frames qui transitent dans un ordre aléatoire au sein de la même connexion TCP. Mais là vous analysez votre flux réseau et vous vous dites : « Pourquoi est-ce que cette image qu'on ne voit pas sur la page d'accueil est toujours chargée avant mon image d’en-tête ? »
Ne serait-il pas merveilleux de pouvoir dire quelles ressources charger en priorité ?
Eh bien c'est justement ce que permet HTTP/2 en offrant la possibilité d'attribuer à chaque stream un poids et une ou plusieurs dépendances envers d'autres streams.
La combinaison de ces deux attributs permet au client de construire un « arbre de priorité » exprimant comment il préfère recevoir la réponse. Le serveur de son côté peut utiliser cet arbre pour affecter plus ou moins de ressources aux streams en fonction de leur importance. Exemple ci-dessous :
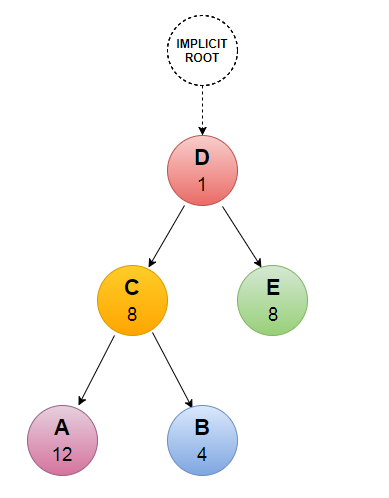
- Etape 1 : la ressource D est la première a être chargée => 100 % des ressources serveur sont attribuées à cette tâche ;
- Etape 2 : D est chargée. D possède une dépendance vers E et C qui possèdent un attribut poids identique (8) => E et C recevront chacune 50 % des ressources serveur ;
- Etape 3 : C est chargée. C possède une dépendance vers A et B. A représentant un poids de 75 % et B de 25 % => A recevra 75 % des 50 % de C et B 25 % des 50 % de C.
Attention toutefois, cet arbre de priorité permet uniquement de définir des préférences. Il n'y a aucune garantie que les ressources seront bien traitées dans cet ordre et cela pour la simple et bonne raison qu'on ne veut pas empêcher le serveur de progresser dans le traitement d'une ressource de second ordre si une autre plus importante se retrouve bloquée.
À noter qu'il existe une proposition en cours d'étude par le W3CWorld Wide Web Consortium concernant la priorisation des ressources :
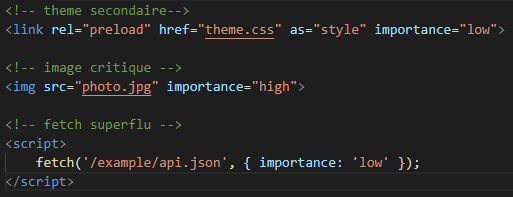
Actuellement, le navigateur attribue une importance par défaut à chacune des ressources. Par exemple une feuille CSS dans la balise head sera toujours chargée en priorité sur une feuille JS, une image aura toujours une priorité moindre, etc.
L'idée à l'étude est de pouvoir modifier cette priorité par l'ajout d'un attribut importance directement dans le code HTML comme dans l'exemple suivant :
II-G. La compression des headers▲
Chaque message HTTP transporte un ensemble de headers sous forme de paires clef/valeur qui décrivent la ressource transférée et ses propriétés.
=> En HTTP 1.1 ces headers sont toujours envoyés au format texte, souvent répétés à l'identique. Si leur taille relativement faible semble insignifiante, le phénomène de répétition auquel on peut ajouter la présence de cookies parfois volumineux, peut avoir un impact conséquent sur la bande passante du réseau.
=> En HTTP/2, les headers sont compressés en utilisant le format de compression HPACK. Ce dernier a été développé spécialement pour HTTP/2 dans une optique d'efficacité, de simplicité de mise en œuvre et surtout de sécurité.
HPACK se base sur deux principes :
- toutes les données sont encodées avec un codage de Huffman ;
- le client et le serveur doivent maintenir une table indexée des headers précédemment rencontrés. Cela permet lors de requêtes successives de n'envoyer que l'index du header déjà fourni et le client/serveur va reconstituer la liste complète des headers en utilisant la table indexée à sa disposition.
II-G-1. Qu'est-ce que cela change la compression des headers ?▲
La compression ajoutée à la suppression des headers redondants entre deux requêtes permet de réduire le temps de chargement d'une page, en particulier dans le cas d'un appareil à faible bande passante. Là aussi, le fait que ce soit un protocole binaire rend la compression plus efficace.
Attention, la table indexée est liée à la connexion. Il est impossible que deux connexions partagent la même table et ceci même si elles pointent vers un même domaine.
Pour la petite histoire, la table indexée ne faisait à l'origine que 4 Ko. Certains headers, comme par exemple le header CSP de Twitter, ont une taille supérieure à 4 Ko ce qui écrasait complètement les autres valeurs. Heureusement, aujourd'hui, cette limite a été augmentée à 65 Ko pour les principaux navigateurs et il est de toute façon possible de configurer la connexion (via une frame SETTINGS) pour exclure certains headers de la table.
II-H. Serveur Push▲
C'est une petite révolution dans la manière de communiquer entre le client et le serveur puisque HTTP/2 permet de rompre avec le modèle requête ? réponse, avec le client qui doit demander chaque ressource et le serveur qui ne peut que répondre à une requête client. Désormais, les ressources peuvent être poussées à l'initiative du serveur alors que le client ne les a pas (encore) demandées.
Dans un premier temps, voyons comment une page se charge de manière traditionnelle :
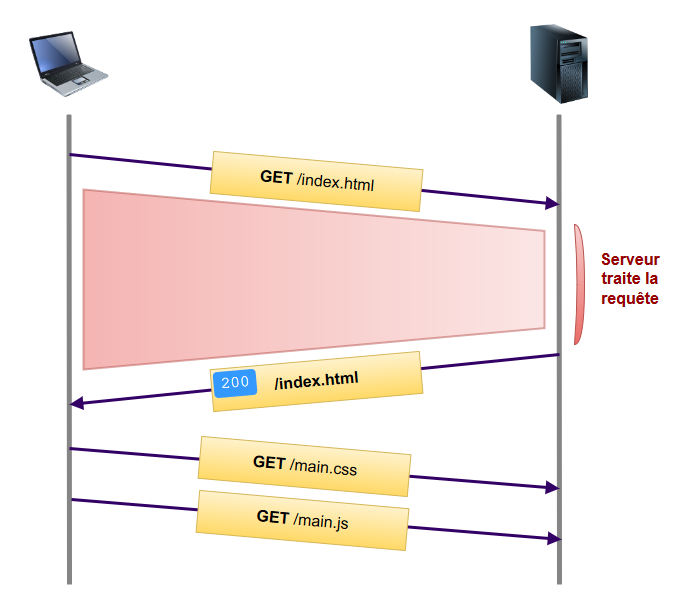
Le client requête la page index.html. Une fois qu'il l'a reçue, il va la parser pour construire le DOM. Dans cette phase de parsing, le navigateur va rencontrer des balises contenant des références vers des fichiers CSS, JavaScript ou encore des images. À chaque fois, le client va donc faire une nouvelle requête pour récupérer la ressource en question.
Le problème est ce temps perdu (identifié par la zone rouge dans le schéma ci-dessus) entre le moment où le client fait la requête initiale et celui où il parse le fichier html et récupère les ressources annexes.
Bien souvent, on sait que pour cette page le client aura également besoin de ce fichier CSS, de ces images, etc. Il faudrait donc pouvoir lui transmettre ces ressources directement, sans qu'il n'ait besoin de les découvrir en examinant la page fournie par le serveur. C'est justement ce que permet la fonctionnalité de serveur Push.
Comment ça fonctionne ?
Le serveur va initialiser un push en créant un nouveau stream et en transmettant au client une frame de type PUSH_PROMISE qui indique ce que le serveur a l'intention d'envoyer. Cette frame contient en fait tous les headers HTTP de la ressource en question. Viennent ensuite les frames DATA classiques.
A la réception de ce PUSH_PROMISE, le client a la possibilité de refuser le stream en transmettant une frame de type RST_STREAM. Cela peut se produire par exemple si le navigateur possède déjà la ressource dans son cache. Voici du coup à quoi ressemble le flux de données :
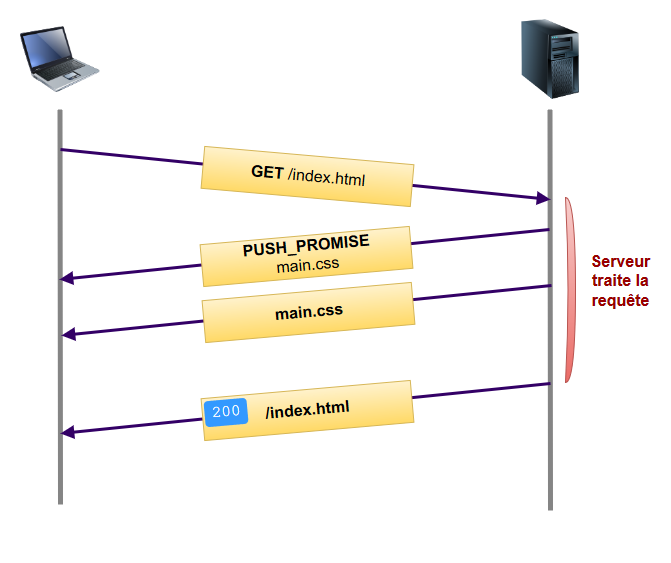
On ne perd plus de temps à attendre de recevoir la page initiale, ici les ressources annexes critiques sont poussées directement par le serveur.
Afin d'éviter un article monolithique, je vais m'arrêter là concernant le serveur Push. Cependant, cette fonctionnalité est beaucoup plus complexe que ça, notamment pour être utilisée de manière efficace. C'est d'ailleurs ce qui explique son très faible taux d'adoption aujourd'hui mais il reste encore de nombreuses évolutions en préparation sur ce sujet ![]() )
)
II-I. Pour finir▲
Une dernière amélioration apportée par HTTP/2 concerne la sécurité. En effet, si aucune obligation de chiffrement des flux n'est présente dans la spécification HTTP/2, la plupart des implémentations (Chrome, Firefox, Safari, Edge, etc.) imposent une communication en HTTPS pour utiliser HTTP/2, rendant l'utilisation du protocole TLS obligatoire de-facto.
II-J. Conclusion▲
HTTP/2 représente une évolution majeure par rapport à HTTP 1.1, même s'il reste du travail encore aujourd'hui, notamment sur la fonctionnalité de Serveur Push.
Le gain en performance ainsi que le chiffrement permettent non seulement une meilleure expérience utilisateur mais également un meilleur référencement SEO, ces deux critères étant largement pris en compte par les moteurs d'indexation.
De plus, son support par un grand nombre de technologies et sa relative facilité de mise en œuvre, rendent son adoption très facile. Il n'y a donc plus à hésiter, sautez le pas !
Pour aller encore plus loin, HTTP/2 n'est même pas encore utilisé partout que déjà la suite se prépare. Si cela vous intéresse, je vous invite à jeter un coup d’œil sur le protocole QUIC lui aussi développé par Google et qui cherche à résoudre le problème que j'ai rapidement évoqué concernant le « Head-of-line blocking » en TCP.
III. HTTP/2 – les anciennes pratiques à éviter▲
Au fil des années et du développement toujours plus rapide d'Internet, les limites du protocole HTTP 1.1 ont commencé à se faire sentir et elles sont devenues une réelle entrave à la performance des sites web. Ainsi, plusieurs techniques de contournement ou hacks sont apparues et sont même devenues des «bonnes pratiques» pour certains.
Toutefois, avec l'arrivée de HTTP/2, ces techniques se révèlent parfois contre-productives. Petit tour d'horizon des pièges à éviter désormais.
III-A. Le domaine sharding▲
En moyenne, 108 ressources sont nécessaires pour l'affichage complet d'une page web. le « Head-of-line blocking » en HTTP nous obligeant à charger ces ressources de manière séquentielle, une première solution consiste à ouvrir plusieurs connexions TCP.
Cependant, comme expliqué ci-dessus, le navigateur limite à six le nombre de connexions TCP ouvertes vers un même domaine.
Pour contourner cela, la technique du « domaine sharding » consiste à distribuer les ressources nécessaires à une page web sur plusieurs domaines.
On peut ainsi paralléliser un peu plus le chargement au prix de connexions TCP et de résolutions DNS supplémentaires.
HTTP/2 à la rescousse
Grâce à son multiplexage de flux, HTTP/2 permet de charger en parallèle toutes les ressources nécessaires à une page via une unique connexion TCP.
III-B. Concaténation des fichiers CSS ou JS▲
Actuellement, en développement front-end, on cherche toujours à regrouper tous les fichiers CSS ou JS voire même des images de faible taille en un seul fichier monolithique, afin d'éviter les multiples requêtes HTTP. Cette concaténation est même effectuée automatiquement lorsqu'on utilise des frameworks comme Angular ou React.
HTTP/2 à la rescousse
Encore une fois, grâce au multiplexage de flux, il n'y a plus aucune raison d'agir ainsi. Charger chacun des fichiers séparément permettra en plus d'utiliser la priorisation des streams, de les mettre en cache et de pouvoir ainsi les réutiliser pour d'autres pages.
Attention toutefois à ne pas tomber dans l'excès en créant des multitudes de micro-fichiers. Il convient d'appliquer cette pratique de manière raisonnée.
III-C. Domaine cookie-less▲
Certains cookies, notamment sur les sites marchands, peuvent devenir assez volumineux. Étant donné qu'ils sont automatiquement ajoutés à chacune des requêtes faites par le navigateur, ils vont de-facto réduire la bande passante disponible pour le reste des données.
Une technique répandue en HTTP 1.1 consiste à faire utiliser un autre domaine par la partie du site web qui n'utilise pas les cookies. Cela permet de ne pas avoir à transmettre de cookies pour des contenus n'en ayant pas besoin.
HTTP/2 à la rescousse
En éliminant les headers redondants et en les compressant, HTTP/2 réduit drastiquement la bande passante utilisée par ces derniers. L'intérêt du domaine « cookie-less » est donc beaucoup moins flagrant, d'autant plus qu'il implique une connexion TCP (et donc une autre table indexée) et une résolution DNS supplémentaire.
III-D. Inlining de fichier▲
En HTTP 1.1, une méthode « d'optimisation » consiste à inclure directement dans la page HTML le code CSS/JS ou d'autres ressources comme des images en utilisant les balises appropriées. Exemple avec un pixel transparent :
<img src="image/gif;base64,R0lGODlhAQABAIAAAAAAAAAAACH5BAAAAAAALAAAAAABAAEAAAICTAEAOw==" alt="1x1 transparent (GIF) pixel" />Cela permet de « pousser » les ressources vers le client sans attendre qu'il les requête.
HTTP/2 à la rescousse
Le serveur Push HTTP/2 permet d'atteindre les mêmes objectifs mais en bénéficiant en plus de la possibilité de :
- mettre en cache dans le navigateur ;
- réutiliser la ressource dans d'autres pages ;
- transmettre le message de manière multiplexée ;
- prioriser le stream ;
- décliner le stream.
III-E. Conclusion▲
Je trouve intéressante la manière dont les différents points ci-dessus mettent en évidence la réelle volonté de l'IETF de venir faciliter le travail des développeurs avec son protocole HTTP/2. Celui-ci vient en effet apporter des solutions différentes des principaux hacks utilisés avec HTTP 1.1. Cela va certes demander du travail pour faire machine arrière sur toutes ces pratiques très utilisées, mais le gain de simplicité que cela apporte devrait finir de convaincre même les plus sceptiques.
IV. HTTP/2 – l’API HTTP Client de Java 11▲
Java 11 propose l'API HTTP Client pour faciliter l'utilisation côté client du protocole HTTP.
Cette API doit remplacer la classe historique HttpURLConnection introduite dans le JDK 1.1. Cette classe possède de nombreux inconvénients notamment :
- son ancienneté et les difficultés pour la maintenir ;
- les difficultés liées à son utilisation ;
- son fonctionnement uniquement en mode synchrone.
L'API HTTP Client a été introduite dans Java 9 sous la forme d'un module incubator : elle était dans la package jdk.incubator.http contenu dans le module jdk.incubator.httpclient.
Elle a connu quelques évolutions pour maintenant être incluse en standard dans un module de Java 11.
IV-A. Présentation de l'API HTTP Client▲
La nouvelle API HTTP Client propose un support des versions 1.1 et 2 du protocole HTTP ainsi que les WebSockets côté client.
L'API est fournie en standard dans Java 11 : son but n'est pas de fournir une implémentation complète des protocoles mais d'être un compromis entre fonctionnalités et consommation de ressources.
Cette API offre une certaine modernité en termes de conception et de mise en œuvre :
- utilisation du patron de conception builder ;
- utilisation de fabriques pour obtenir des instances , mais aussi des instances d’'implémentation de certaines interfaces pour des usages courants ;
- utilisation de l'API Flow (reactive streams) pour fournir les données du body d'une requête (Flow.Publisher) et consommer le body d'une réponse (Flow.Subscriber).
L'API est contenue dans le package java.net.http du module java.net.http. Elle contient plusieurs types (interfaces, classes, énumération, exceptions) dont les principaux sont :
|
Classe/Interface |
Rôle |
|---|---|
|
HttpClient |
Instance immuable qui permet l'envoi d'une requête et la réception de la réponse correspondante en mode synchrone ou asynchrone |
|
HttpClient.Builder |
Builder pour configurer et obtenir une instance de type HttpClient |
|
HttpRequest |
Instance immuable qui encapsule une requête (URI, verbe (GET, POST, PUT, DELETE…), headers…) |
|
HttpRequest.Builder |
Builder pour configurer et obtenir une instance de type HttpRequest |
|
HttpRequest.BodyPublisher |
Fournit le contenu du body à la requête si elle en a besoin (requêtes de type POST et PUT) à partir de différentes sources |
|
HttpRequest.BodyPublishers |
Une fabrique d’objets pour obtenir des instances de type BodyPublishers pour des usages courants (chaîne de caractères, fichier…) |
|
HttpResponse |
Encapsule la réponse obtenue d’une requête envoyée (code statut, headers, body…) |
|
HttpResponse.ResponseInfo |
Encapsule le code statut et les headers de la réponse |
|
HttpResponse.BodySubscriber |
Consomme les octets du body d'une réponse pour les convertir en objet Java (chaîne de caractères, fichier…) |
|
HttpResponse.BodySubscribers |
Une fabrique d’objets pour obtenir des instances de type BodyHandler pour des usages courants |
|
HttpResponse.BodyHandler |
Interface fonctionnelle qui permet de gérer une réponse à partir des informations d'une ResponseInfo. Elle renvoie un BodyPublisher pour traiter le body de la réponse |
|
HttpResponse.BodyHandlers |
Propose des fabriques pour des BodyHandler courants |
IV-B. La classe HttpClient▲
L'obtention d'une instance de type HttpClient peut se faire de deux manières :
- l'utilisation de la fabrique newHttpClient() de la classe HttpClient pour obtenir une instance avec la configuration par défaut
HttpClient client = HttpClient.newHttpClient();- l'utilisation de l'interface HttpClient.Builder qui est un builder pour configurer l'instance obtenue. Une instance du Builder est obtenue en utilisant la fabrique newBuilder() de la classe HttpClient
HttpClient httpClient = HttpClient.newBuilder()
.version(HttpClient.Version.HTTP_1_1)
.build();La classe HttpClient utilise par défaut la version 2 du protocole HTTP.
Il est possible de préciser un proxy grâce à la méthode proxy() en lui passant en paramètre une instance de type ProxySelector
HttpClient httpClient = HttpClient.newBuilder()
.version(HttpClient.Version.HTTP_1_1)
.proxy(ProxySelector.of(new InetSocketAddress("proxy.oxiane.com", 80)))
.build();IV-C. La classe HttpRequest▲
Elle encapsule une requête à envoyer à un serveur.
Une instance de type HttpRequest est obtenue en utilisant un builder de type HttpRequest.Builder. Une instance de l'interface HttpRequest.Builder est obtenue en utilisant la fabrique newBuilder() de la classe HttpRequest.
Plusieurs méthodes permettent de configurer les éléments de la requête : l'uri, le verbe HTTP, les headers, un timeout.
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://www.oxiane.com/"))
.GET()
.build();La méthode build() permet d'obtenir l'instance.
Pour les requêtes de type POST et PUT, il est possible de fournir le contenu du body en utilisant un BodyPublisher. Un BodyPublisher permet de fournir les données qui seront contenues dans le body à partir d'une source.
La classe BodyPublishers propose des fabriques pour obtenir des instances de type BodyPublisher pour des besoins standards
HttpRequest requetePost = HttpRequest.newBuilder()
.uri(URI.create("https://www.oxiane.com/api/formations"))
.setHeader("Content-Type", "application/json")
.POST(BodyPublishers.ofString("{"cle1":"valeur1", "cle2":"valeur2"}"))
.build();IV-D. L'envoi de la requête et la réception de la réponse▲
Ils peuvent se faire de deux manières :
- synchrone : l'envoi de la requête bloque les traitements jusqu'à la réception de la réponse ;
- asynchrone : la requête est envoyée et le traitement de la réponse est effectué par un CompletableFuture.
IV-E. L'envoi en mode synchrone▲
Il se fait en utilisant la méthode send() de la classe HttpClient. Elle attend en paramètres :
- la requête ;
- une instance de type HttpResponse.BodyHandler qui permet de traiter le body selon la réponse.
La classe HttpBodyHandlers propose des fabriques pour obtenir des instances de BodyHandler pour des usages courants.
HttpResponse response;
try {
response = httpClient.send(requete, BodyHandlers.ofString());
System.out.println("Status : " + response.statusCode());
System.out.println("Headers : " + response.headers());
System.out.println("Body : " + response.body());
} catch (IOException | InterruptedException e) {
e.printStackTrace();
}IV-E-1. L'envoi en mode asynchrone▲
Il se fait en utilisant la méthode sendAsync() de la classe HttpClient. Cette méthode attend en paramètres :
- la requête ;
- une instance de type HttpResponse.BodyHandler qui permet de traiter le body selon la réponse.
La méthode retourne un CompletableFuture qui permet de définir les traitements à exécuter à réception de la réponse.
httpClient.sendAsync(requete, BodyHandlers.ofString()).thenAccept(response -> {
System.out.println("Status : " + response.statusCode());
System.out.println("Headers : " + response.headers());
System.out.println("Body : " + response.body());
});IV-F. Conclusion▲
La nouvelle API HTTP Client de Java 11 propose en standard des facilités pour envoyer des requêtes HTTP et traiter leur réponse avec une API moderne. Le support de HTTP/2 et des WebSockets permet la mise en œuvre de clients sans avoir recours à des bibliothèques tierces.
V. HTTP/2 – serveur push▲
En réalité, le réseau est généralement plus complexe que ça et ne se limite pas à un client et un serveur discutant l'un avec l'autre. Bien souvent, afin de réduire au maximum la latence lors du chargement des ressources, les principaux assets sont « délocalisés » dans un CDN ou Reverse Proxy. Une représentation plus réaliste des flux ressemble donc à ça :
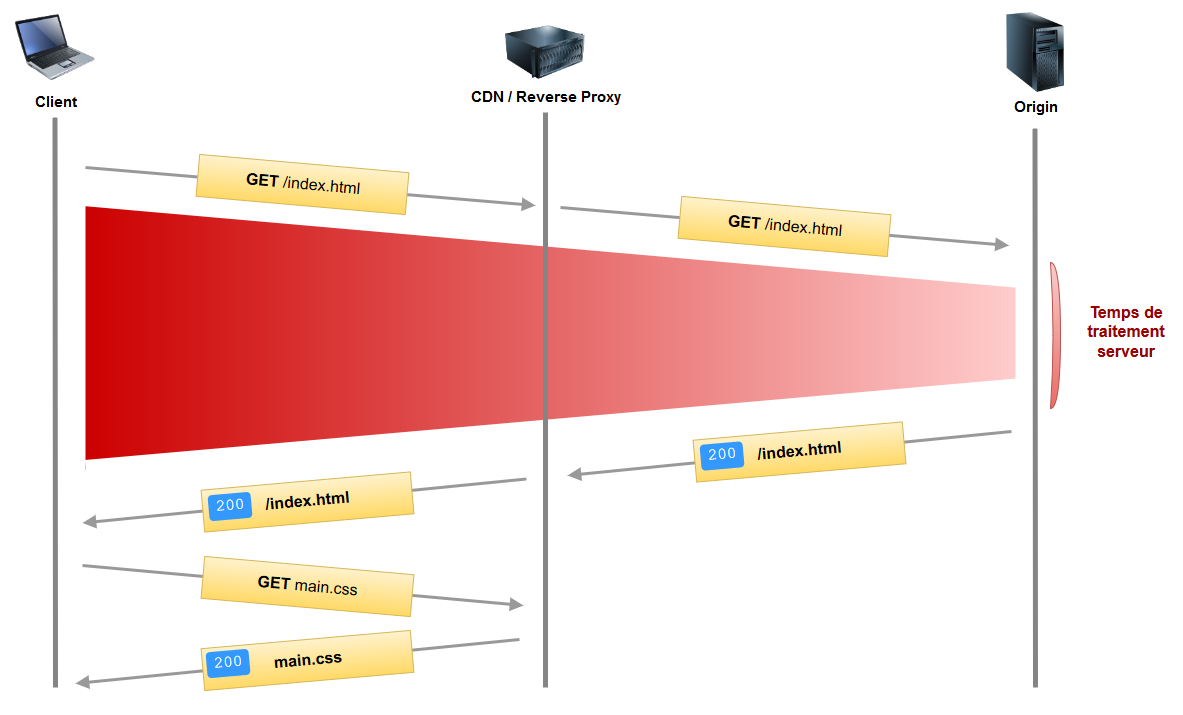
V-A. Serveur push, pourquoi faire ?▲
Sur le schéma ci-dessus, vous vous rendez compte du problème : du temps perdu lors de la requête initiale (en rouge sur le schéma) et des ressources qui ne sont découvertes que lors du parsing du code HTML reçu (la feuille CSS dans notre cas). Pire encore, notre page pourrait comporter des « sous-ressources critiques cachées » et là, en termes de performances, c'est le drame.
Des quoi ?
Pour comprendre de quoi il s'agit, voici un petit rappel sur le fonctionnement du navigateur.
Afficher un page classique nécessite principalement deux ressources : une page HTML avec laquelle on va construire le DOM et une feuille de style avec laquelle on va construire le CSSOM.
DOM et CSSOM sont ensuite combinés pour former le Render Tree.
À partir du Render Tree, le navigateur peut procéder à l'étape de First Paint de la page, étape durant laquelle il effectue la mise en page et peint le contenu.
Puis on passe à l'étape suivante, Text Paint, qui peint les pixels de texte.
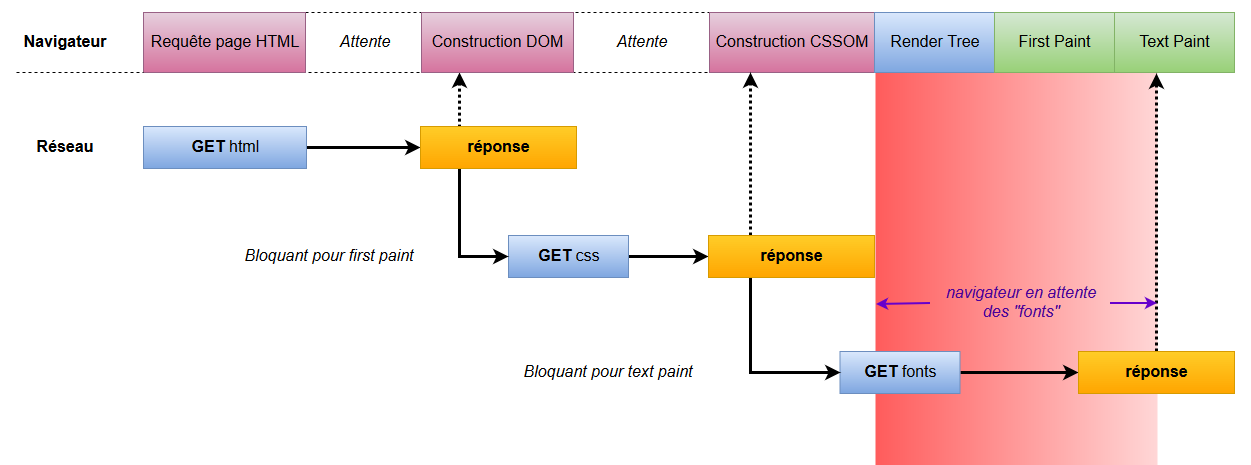
La différence entre le code HTML et CSS, c'est que lorsque le navigateur reçoit une page HTML, il peut commencer à construire le DOM au fur et à mesure que les bits arrivent du serveur, sans avoir besoin d'attendre que tout le code lui soit parvenu.
En revanche, pour une feuille CSS, ce n'est pas possible en raison de la manière dont la cascade fonctionne (on obtiendrait des flashs et « repaint » successifs au niveau de la page). Il faut donc attendre d'avoir reçu le code CSS complet avant de créer le Render Tree et ce n'est qu'à cette étape que le navigateur va récupérer les fonts dont il a besoin pour passer à l'étape de Text Paint.
En effet, une feuille CSS peut renseigner une multitude de fonts, mais seulement 2 ou 3 seront utiles pour ma page et ça, pour le savoir, le navigateur a besoin du Render Tree.
Voilà pourquoi les fonts sont généralement ce qu'on appelle des « sous-ressources critiques cachées » : « critiques » car nécessaire au rendu initial de ma page et « cachées » car elles ne sont découvertes (et donc récupérées) que très tard dans le processus d'affichage.
Comment faire alors pour indiquer au navigateur que ces ressources sont essentielles et ainsi améliorer les performances d'affichage de ma page ? Le serveur push vient justement répondre à ce genre de besoin.
V-B. Optimisation – Level 1 : Preload API▲
Cela consiste à déclarer les ressources que l'on veut précharger pour la page en cours et uniquement la page en cours (il existe aussi une API prefetch qui permet de charger des ressources utiles pour la future navigation).
Cela peut se présenter sous la forme :
- d'un header :

- d'une balise dans le code HTML ou dans un script JS :
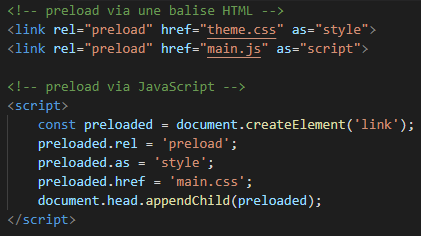
L'attribut as définit le type de ressource, permettant au navigateur d'appliquer la bonne priorité à la ressource. L'attribut crossorigin, quant à lui, est obligatoire pour les fonts (voir documentation MDN). Ainsi notre flux devient :
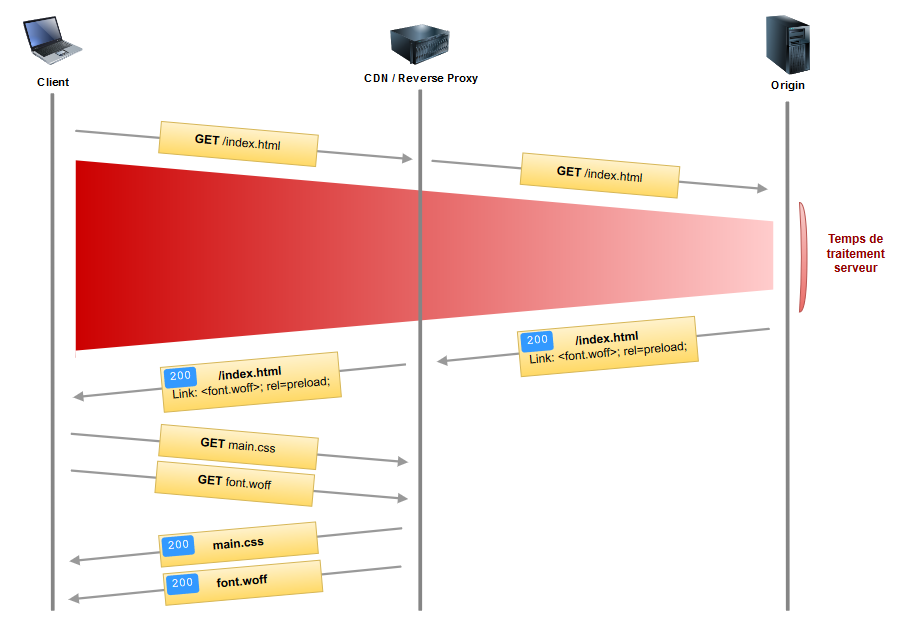
preload permet d'améliorer les performances de chargement d'un site en déclarant les ressources dont on sait que la page va avoir besoin afin que le navigateur les précharge. Dans l'exemple ci-dessus, fonts et feuille CSS sont reçues en même temps par le navigateur au lieu d'avoir à demander les fonts une fois que le parsing du CSS est terminé. On gagne ainsi 1 RTT (comprendre un aller-retour client-serveur correspondant à la requête et la réponse pour les fonts).
À titre d'exemple, Shopify a constaté une amélioration d'environ 50 % (1.2 s) sur le délai de Text Paint, simplement en ajoutant cette petite ligne de code préchargeant ses fonts. 50 % pour quelques balises HTML supplémentaires, je dirais que c'est plutôt rentable.
J'ai fait le test moi-même sur le site sur lequel je travaille :

La première requête utilise preload, les autres non. Sachant que le site n'est pas non plus énorme en termes de ressources (58 requêtes au total, temps de chargement de la page : 850 ms) je trouve quand même la différence assez importante.
Une question toutefois : la requête générée par le preload n'arrive-t-elle pas encore trop tard ? On gagne certes du temps par rapport à notre flux de requêtes initial mais on doit quand même attendre de découvrir les balises ou headers preload au moment où on reçoit la page HTML…
De plus, vous l'avez sans doute remarqué, à aucun moment je ne mentionne le serveur push et ça pour la simple et bonne raison que preload n'est pas du serveur push. Cette API est même bien antérieure à HTTP/2 ; alors pourquoi je vous parle de tout ça ? Et bien en fait c'est directement lié, car une manière d'utiliser le serveur push est justement de se baser sur ces headers preload.
V-C. Optimisation – Level 2 : Serveur Push▲
Le CDN/Reverse Proxy se base sur les headers preload pour pousser (« push ») les assets vers le client. Démonstration :
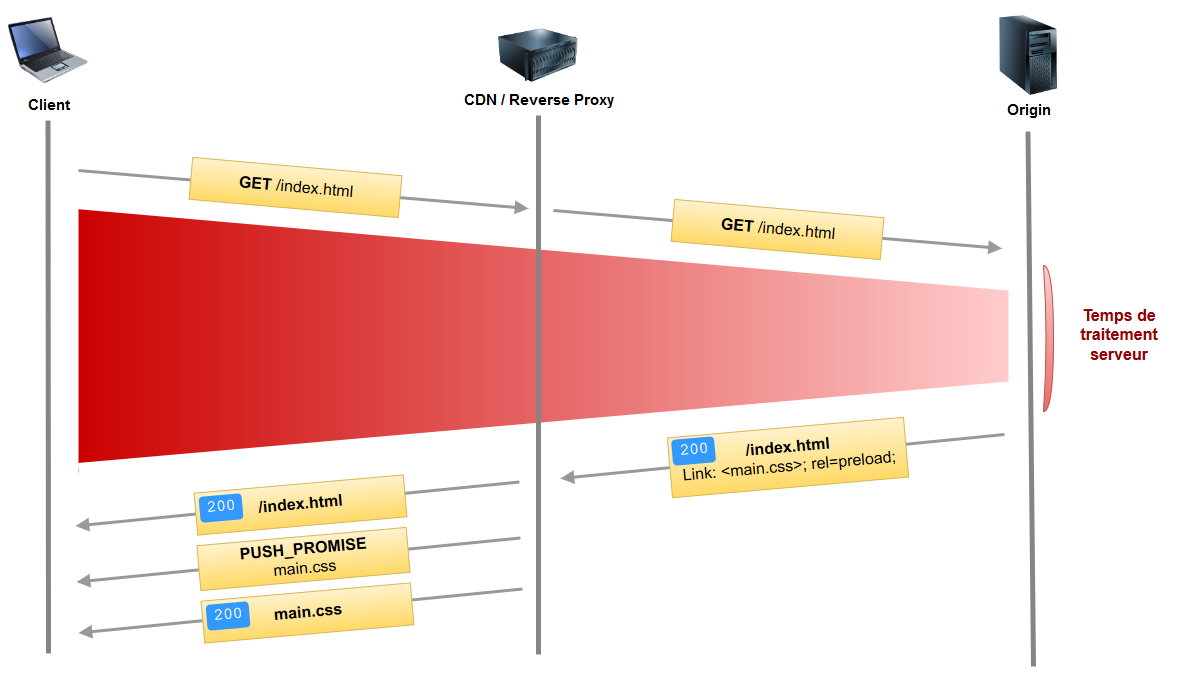
On gagne là aussi 1 RTT : la feuille CSS est directement poussée (« push ») par le CDN/Reverse Proxy et reçue par le navigateur en même temps que la page index.html.
Une critique cependant : cela ne résout pas le problème de notre temps d'attente lors de la requête initiale. N'y a-t-il pas moyen d'utiliser ce temps de latence ?
V-D. Optimisation – Level 3 : Async Push▲
En réalité je ne suis pas sûr que cette technique ait un nom. J'en ai vu plusieurs allant du « hard push » au « async push » et je trouve que celui-ci est assez parlant.
Cela consiste à configurer notre CDN/Reverse Proxy pour qu'en cas de requête, par exemple vers la page index.html, il exécute un « push » automatique de certains assets.
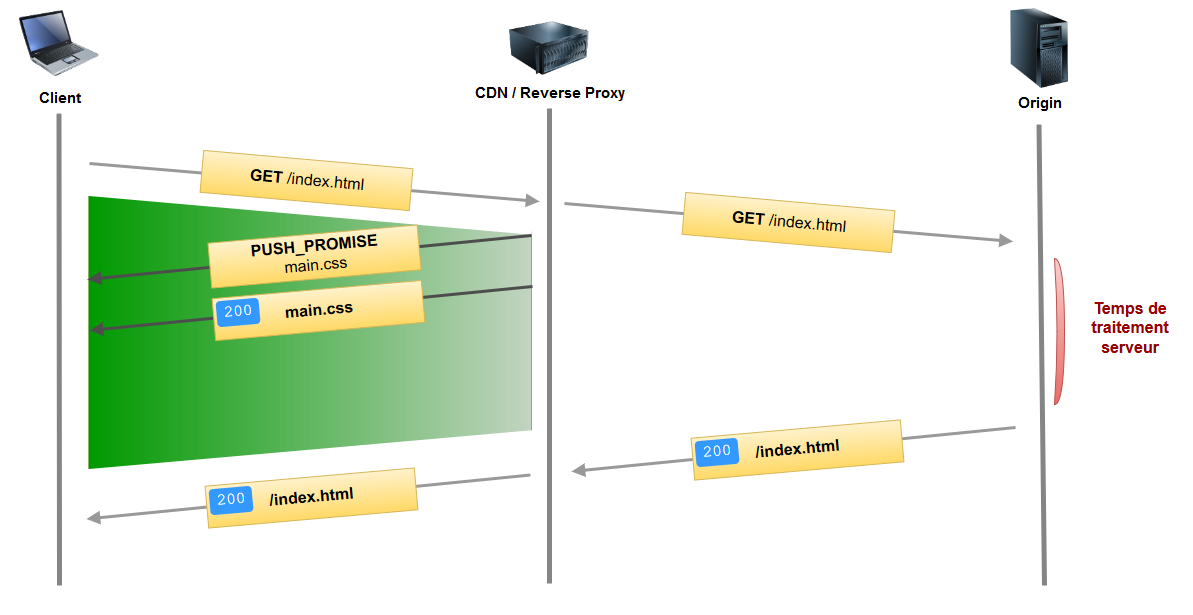
Plus de temps perdu à attendre. Le temps de latence lors de la requête initiale est rentabilisé. Le navigateur aura tout ce dont il a besoin lorsqu'il aura fini d’analyser le code HTML.
Tout semble parfait désormais, on dirait bien que nous avons réussi à tirer le meilleur parti de ce serveur push. Ce n'était pas si compliqué finalement… Oh ! Attendez, je crois qu'on oublie un détail…
V-E. Le cache▲
C'est là que notre trouble-fête entre en action. Que se passe-t-il en cas de vues répétées sur la page ?
- Avec HTTP 1.1, chaque ressource est récupérée via une connexion TCP propre et mise en cache (cela dépend des « caching headers »). En cas de vues répétées, le navigateur ira chercher la ressource dans le cache, évitant ainsi un nombre important de requêtes.
- Avec HTTP/2 et le serveur push, en cas de vues répétées, et bien on exécute quand même un push. Certes, on n’a pas à supporter le coût de l'ouverture de multiples connexions TCP puisque tout se fait au sein de la même connexion, il n'en reste pas moins qu'il s'agit de données superflues entraînant un risque de congestion au niveau du réseau.
Bien sûr, le client a la possibilité de décliner un push s'il possède déjà la ressource en cache. Pour cela, à la réception de la frame PUSH_PROMISE émise par le serveur, il doit envoyer une frame RST_STREAM. Cependant, il n'a aucun délai imparti pour faire ça : la frame PUSH_PROMISE est immédiatement suivie des frames DATA constituant la ressource. Une course se lance donc entre la frame RST_STREAM et le transfert de la ressource.
Étant donné que l'on aura tendance à exécuter un « push » des ressources critiques pour le rendu de la page et que généralement celles-ci ont une taille relativement faible, c'est malheureusement le RST_STREAM qui va perdre la course et les données seront quand même transférées.
Voilà pourquoi le serveur push est bien souvent source de régression plutôt que d'amélioration.
Ce n'est pas tout, car on parle souvent de cache navigateur, or il faut savoir que le navigateur possède non pas un unique cache mais plusieurs… De quoi rendre les choses encore plus complexes.
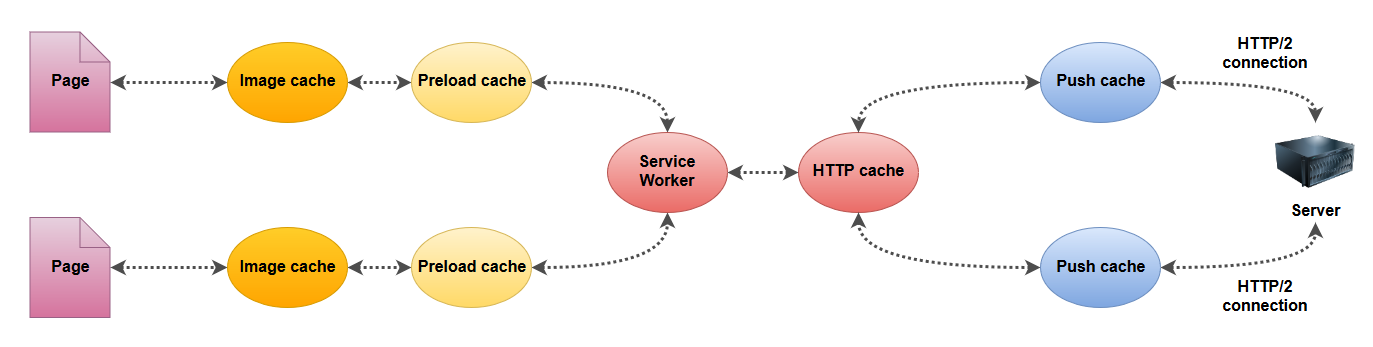
Certains caches sont liés au contexte de la page, d'autres au contexte de la connexion HTTP/2 et d'autres encore sont communs. Qu'est-ce que ça implique pour nous ?
V-E-1. Push cache lié à la connexion▲
En ce point réside déjà notre première difficulté. Et là vous vous dites : « Quel est le problème ? tu nous as dit qu'en HTTP/2 on utilisait une seule connexion TCP !? »
Et bien c'est vrai… en partie.
Imaginez que vous soyez sur un réseau pas très fiable, dès que vous perdez la connexion vous perdez également le cache…
Autre cas plus complexe : les requêtes avec et sans « credentials »
Les « credentials » sont des données (généralement des headers) que le navigateur envoie avec la requête et qui identifie l'utilisateur (cookies, basic auth, certificats…).
La plupart des requêtes sont en mode « credentialed » mais, vous vous en doutez, pas toutes. Les requêtes fetch ou celles concernant des fonts ne le sont pas.
Résultat : une même ressource, qu'elle soit push ou récupérée par un fetch, ne partagera pas le même cache.
V-E-2. Push cache en dernière position▲
Le push cache est le dernier à être vérifié par le navigateur avant d'envoyer la requête. Si par exemple vous avez une ressource dans votre cache HTTP, vous pouvez toujours essayer de faire un « push » de la même ressource, plus récente, pour la rafraichir, elle ne sera jamais prise en compte car le navigateur s'arrêtera à celle qu'il trouve dans le cache HTTP.
V-E-3. Ressource utilisable une seule fois▲
Chaque item dans le push cache est utilisable de manière unique puis est retiré du cache (il est toutefois possible qu'il soit ensuite placé dans le cache HTTP, cela dépendra des « caching headers »).
V-E-4. Et enfin, le cache n'est pas standardisé▲
Il n'y a aucune spécification concernant l'implémentation du cache et la conséquence est que le comportement varie selon les navigateurs.
Cela va de Edge ayant un support pauvre de la fonctionnalité (mais au moins pauvre de manière constante) à Safari qui, lui, a une approche complètement non déterministe (comprendre des fois ça marche, des fois ça ne marche pas), en passant par Chrome et Firefox qui sont les seuls à assurer un bon support de la fonctionnalité.
Attention « bon support » ne veut pas dire parfait. Certains exemples sont assez croustillants, notamment Firefox qui, lors d'un RST_STREAM (indiquant qu'il a déjà la ressource dans son cache) va « drop » non seulement le stream mais également la ressource dans son cache, le laissant avec … rien du tout !
Si vous souhaitez aller plus loin concernant le support du serveur push sur les différents navigateurs, il y a un excellent article de Jake Archibald qui détaille tout ça.
La seule solution pour pallier ces différences d'implémentation serait de faire du « UA sniffing », ce qui revient à appliquer différentes politiques au niveau du serveur en fonction du navigateur (et de sa version) client. ![]()
« Bon c'est bien de lister tout ce qui ne va pas avec le serveur push, mais nous, comment on l'utilise ? »
A l'heure actuelle, les solutions (simples) ne sont pas très nombreuses et c'est certainement ce qui explique le très faible taux d'adoption de la fonctionnalité.
V-E-5. PRPL Pattern▲
C'est un pattern développé par Google qui permet une utilisation efficace du serveur push. Toutefois cela nécessitera d'avoir à votre disposition un Service Worker. C'est donc particulièrement adapté aux PWAs qui, Ô surprise, sont aussi développées par Google. ![]()
PRPL signifie :
- Push critical resources for the initial URL route ;
- Render initial route ;
- Pre-cache remaining route ;
- Lazy-load and create remaining routes on demand.
L'idée consiste à exécuter un « push » uniquement des ressources critiques pour le rendu initial de la page. Puis on utilise le Service Worker pour mettre en précache le reste des ressources et on ne charge les pages qu'à la demande de l'utilisateur.
On remarque quand même une utilisation pour le moins prudente du serveur push qui ne va vraiment être utilisé qu'à l'initialisation de l'application et pour le moins de ressources possible. Le reste est ensuite géré par le Service Worker.
Devant toutes ces difficultés, on peut et on doit se demander : « est-ce que le jeu en vaut la chandelle, est-ce que le gain attendu vaut toute cette complexité supplémentaire ? » À cette question je n'ai pas de réponse, si ce n'est vous rappeler que la fonctionnalité est encore en pleine évolution et que des améliorations sont à prévoir.
V-F. Le Futur▲
Tout le problème du serveur push réside dans le fait que le serveur ne sait pas ce que le client a dans son cache et va donc systématiquement faire un « push » de toutes les ressources.
Comment pourrait-on faire en sorte que le serveur ne le fasse que quand c’est nécessaire ?
V-F-1. Cache Digest▲
Comment ça marche ? Le client transmet à chaque requête une frame de type CACHE_DIGEST indiquant au serveur le contenu du cache navigateur. Le serveur, auquel on va donc devoir rajouter une couche de logique pour gérer ce CACHE_DIGEST, peut ainsi sélectionner uniquement les ressources pertinentes pour les push vers le client.
La spécification en est actuellement au stade expérimental.
Toutefois un certain nombre de critiques s'élèvent déjà concernant la complexité de ce principe et surtout sur le fait que cela revient à gérer un « state » au niveau de la connexion dans un protocole HTTP résolument « stateless ».
V-F-2. 103 Early Hints▲
Autre spécification au stade expérimental qui consiste pour le serveur à envoyer, dès la réception de la requête client, une réponse immédiate avec un code 103 indiquant quelles ressources seront nécessaires. Puis, dans un deuxième temps, le serveur enverra la réponse classique 200 contenant les données.
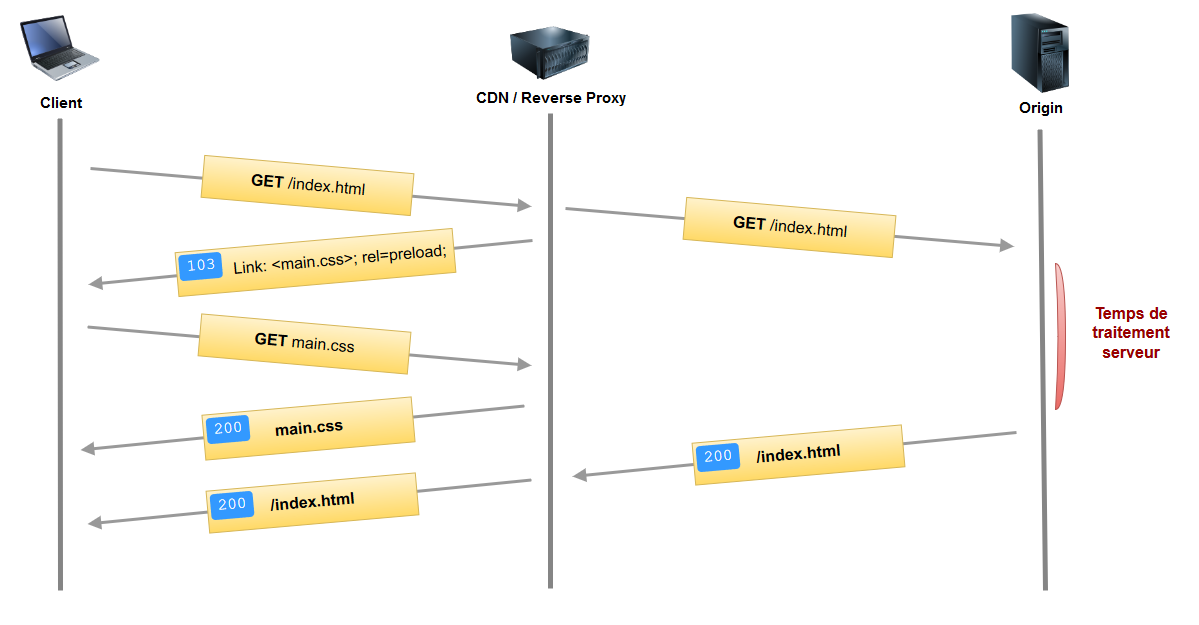
Cela permet, contrairement au cache digest, de laisser la gestion du cache à la charge du navigateur.
À noter que cette fonctionnalité ne fait pas du tout appel au serveur push.
Le fait qu'un grand nombre de proxy ne comprennent pas les réponses de la plage des 100 peut éventuellement poser problème. Toutefois l'utilisation du protocole TLS, qui est pour le moins déjà fortement encouragée, résoudra le souci.
V-G. Conclusion▲
La fonctionnalité de serveur push est encore en pleine évolution mais on peut dire que pour l'instant, à moins d'avoir une PWA, elle est très compliquée à utiliser de manière efficace sans introduire de régression. La mise en place nécessite une bonne compréhension du fonctionnement interne de HTTP/2 mais aussi de la gestion du cache côté navigateur. Nul doute cependant que cette fonctionnalité va s'améliorer dans les années à venir afin de proposer aux développeurs une implémentation plus viable.
Personnellement, même si ce n'est pas lié au serveur push, j'aime beaucoup l'idée du « 103 Early Hints » que je trouve simple et élégante. A voir si cela deviendra le nouveau standard ou si le serveur push parviendra à s'imposer.
VI. HTTP/2 – Server Push avec Java EE 8▲
L'API Servlet de Java EE 8 propose un support d'HTTP/2 et en particulier du Server Push.
Comme expliqué dans la précédente section, le Server Push permet au serveur d'envoyer de manière pro-active des ressources au client. Les ressources ainsi envoyées peuvent alors être stockées par le client et ainsi éviter l'envoi de requêtes.
Évidemment, cela requiert de la part du serveur de connaître les ressources dont le client va avoir besoin pour les lui envoyer par anticipation.
VI-A. Le support du Server Push dans HTTP/2▲
L'API Servlet 4.0 de Java EE 8, définie dans la JSR 369, propose un support de HTTP/2. L’essentiel du support HTTP/2 est pris en charge par l'implémentation de l'API Servlet utilisée. La partie la plus visible de ce support dans l'API est la possibilité d'utiliser le Server Push.
Le serveur peut anticiper l’envoi des ressources liées à celles demandées en utilisant la fonctionnalité Server Push d'HTTP/2.
Cela permet à un navigateur de mettre ses ressources en cache et d’éviter ainsi des requêtes supplémentaires. Ces ressources peuvent être de différentes natures mais par exemple, pour une page HTML, on pourrait retrouver des feuilles de style CSS, des images, des fichiers JavaScript… Le temps de téléchargement des ressources est alors réduit, ce qui améliore le confort utilisateur.
L'utilisation du Server Push implique donc que le serveur connaisse les ressources associées à la requête initiale pour lui permettre de les envoyer de manière proactive si le protocole est supporté.
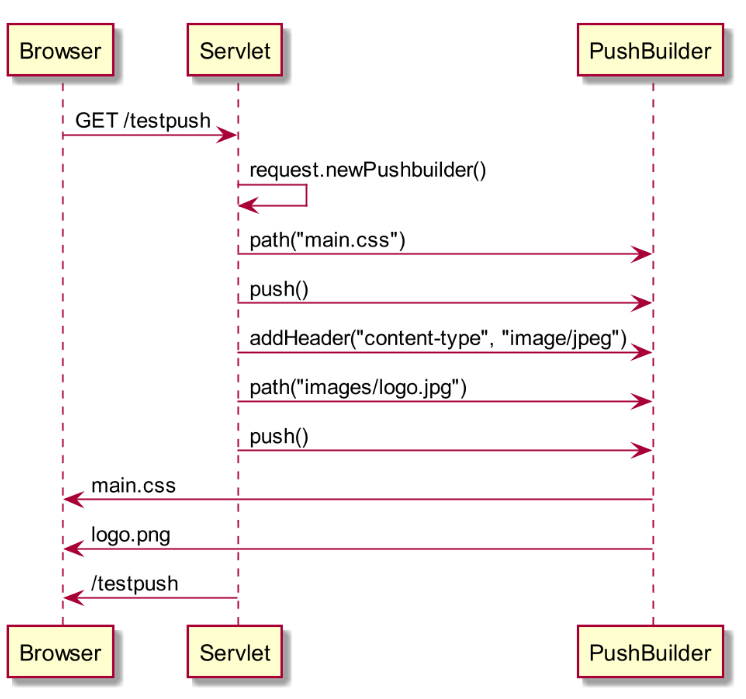
La mise en œuvre requiert l'obtention d'une instance de type PushBuilder à partir de l'HttpServletRequest.
Exemple : invocation d'une servlet qui renvoie une page HTML ayant besoin d'une feuille de styles CSS et d'une image
VI-B. L'interface javax.servlet.http.PushBuilder▲
Pour la mise en œuvre du Server Push, l'API Servlet 4.0 propose l'interface javax.servlet.http.PushBuilder. Cette interface met en œuvre le design pattern builder.
Une instance de type PushBuilder est obtenue en invoquant la fabrique getPushBuilder() de la classe HttpServletRequest.
L'instance obtenue possède une configuration par défaut :
- le verbe HTTP est GET ;
- quelques headers sont initialisés.
Pour chaque ressource à envoyer, il faut configurer le PushBuilder. La seule configuration obligatoire est l'URI de la ressource en utilisant la méthode path().
Il est aussi possible de configurer plusieurs informations sur la ressource :
- des headers avec les méthodes addHeader(), setHeader() et removeHeader() ;
- le verbe à utiliser avec la méthode method() ;
- les paramètres de la requête avec la méthode queryString().
Les invocations de chacune de ces méthodes peuvent être chaînées.
Une fois la configuration terminée, l'invocation de la méthode push() permet d'envoyer la ressource.
L'instance de type PushBuilder peut être réutilisée : sa configuration est conservée sauf l'URI et les headers de type conditional.
Attention : comme indiqué dans la première section de cet article, les principaux navigateurs ne mettent en œuvre HTTP/2 qu'au travers d'une connexion sécurisée.
Si la connexion n'est pas sécurisée ou si le client a désactivé le serveur push dans la requête, alors la méthode newPushBuilder() renvoie « null ». Il faut donc vérifier si l‘instance obtenue n'est pas « null » avant son utilisation.
VI-C. Un exemple de mise en œuvre▲
La servlet ci-dessous renvoie une page HTML avec éventuellement la feuille de style CSS et l'image qu'elle requiert si le mode Push est utilisable.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
import static java.nio.charset.StandardCharsets.UTF_8;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.PushBuilder;
import javax.ws.rs.core.MediaType;
@WebServlet(urlPatterns = "/testpush")
public class PushServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse res)
throws IOException, ServletException {
PushBuilder pushBuilder = req.newPushBuilder();
if (pushBuilder != null) {
System.out.println("Utilisation du push server : "+req.getProtocol());
pushBuilder.path("main.css").push();
pushBuilder.addHeader("content-type", "image/jpeg").path("images/logo.jpg").push();
}
res.setContentType(MediaType.TEXT_HTML_TYPE.withCharset(UTF_8.name()).toString())
res.setStatus(200);
try(PrintWriter resWriter = res.getWriter();){
resWriter.println("<html><head><title>HTTP2 Push</title><link rel="stylesheet" href="main.css"></head>");
resWriter.println("<body>Servlet Push</body><img src="images/logo.jpg" alt="logo" /></html>");
}
}
}
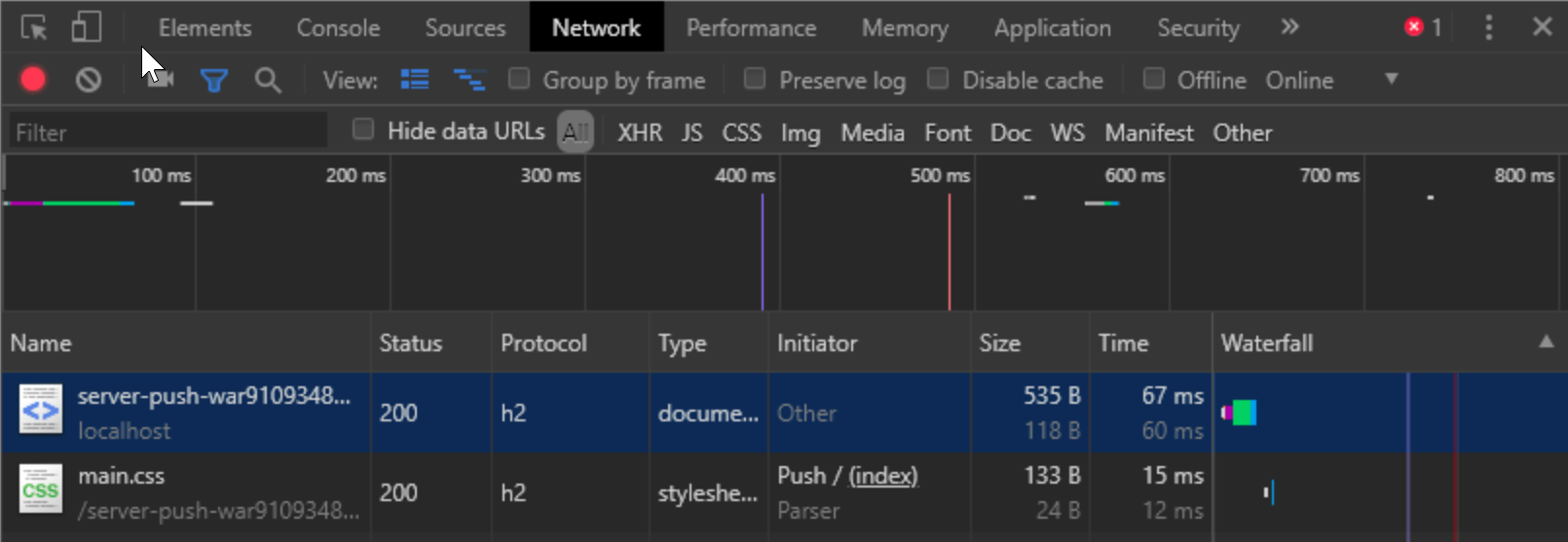
Il est possible d'utiliser les outils de développement des navigateurs pour visualiser les échanges réseau
Exemple avec Chrome Dev tools :
VI-D. L'utilisation du Push Server dans un filtre▲
Il est aussi possible d'utiliser le Push Server dans un filtre de Servlet. Cela permet d'appliquer le Push Server sur différentes ressources.
Il suffit d'utiliser l'interface PushBuilder dans la méthode doFilter() du filtre pour envoyer les ressources selon l'URI de la requête.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
import java.io.IOException;
import javax.servlet.Filter;
import javax.servlet.FilterChain;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.annotation.WebFilter;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.PushBuilder;
@WebFilter("/*")
public class PushFilter implements Filter {
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
HttpServletRequest httpRequest = (HttpServletRequest) request;
String uri = httpRequest.getRequestURI();
System.out.println("Filtre pour uri " + uri + " : " + request.getProtocol());
switch (uri) {
case "/serverpush/maservlet":
PushBuilder pushBuilder = httpRequest.newPushBuilder();
if (pushBuilder != null) {
System.out.println("Utilisation du push server pour uri " + uri + " : " + request.getProtocol());
pushBuilder.path("main.css").push();
pushBuilder.addHeader("content-type", "image/jpeg").path("images/logo.jpg").push();
}
break;
default:
break;
}
chain.doFilter(request, response);
}
}
VI-E. Le support de PushBuilder dans Spring MVC▲
Spring MVC propose un support de l'API Servlet 4.0.
Pour obtenir une instance de type PushBuilder, il suffit de demander son injection en définissant un paramètre de type PushBuilder à une méthode annotée avec @RequestMapping.
VI-F. Conclusion▲
L'API Servlet 4.0 propose un support d'HTTP/2 côté serveur avec notamment une certaine facilité pour mettre en œuvre le Server Push.
VII. Conclusion générale et remerciements▲
Cet article a été publié avec l'aimable autorisation de la société OxianeOxiane, le billet original peut être trouvé sur le blog de OxianeBlog de Oxiane.
Nous tenons à remercier escartefigue pour sa relecture orthographique attentive de cet article puis WinJerome et Mickael Baron pour la mise au gabarit du billet original.